


Introduction
API stands for Application Programming Interface. It describes how two or more software communicate with each other by way of requests and responses. Many large applications are integrated with at least one API. By following a given API’s specifications, a program can retrieve data from the API or modify data on the API’s server.
Objectives
In this article, you will learn how to make API calls in Python using the urllib.request and requests modules.
Prerequisites
To follow along with this tutorial, you need to:
have a basic knowledge of Python
know how to read API documentations
Approach
The focus of this article will be only on GET requests. Using a functional programming approach, this article will demonstrate how to query APIs by solving some related tasks. The JSONPlaceholder API will be used for these demos.
The urllib.request module
urllib.request is a Python module that can fetch and open URLs. The urlopen() method of this module is used to get the content of a web page at a given URL. It accepts a number of arguments but only the url argument is relevant to the current discussion:
urlopen(url, ...)
Check out this tutorial on urllib.request from the official Python documentation to learn more about this module and the urlopen() method.
url is a string describing the URL of the web page you want to access.
To use the urllib.request module, you must first import it:
import urllib.request
You can then call the urlopen method, passing it the URL you want to open:
with urllib.request.urlopen('https://jsonplaceholder.typicode.com/posts/') as response:
# some more code
You can also directly import the urlopen method:
from urllib.request import urlopen
with urlopen('https://jsonplaceholder.typicode.com/posts/') as response:
# some more code
response is an HTTPResponse object. It is similar to a file object, so you may call file object methods, such as read(), on it.
How to query API using the urllib.request module
As already stated, the JSONPlaceholder API is used in this tutorial. The API guide shows the relationship between the different paths and how to make various types of requests (GET, POST, etc.). The focus of this article is only GET requests. Let’s begin with the first task.
TASK 1. Given the JSONPlaceholder API, write a function that returns all the information about a post with a given ID.
Solution. Let the function prototype be get_post_by_id(id).
Here are the steps (or pseudocode):
Import the
jsonmodule and theurlopenfunction from theurllib.requestmoduleValidate that
idis an integer (or can be converted to an integer, e.g. '6') in the range 1–100 (there are 100 posts)Use
urlopento get the HTTP response for the given post URLCall the
read()method on the response to convert it to a byte stringUse the
json.loads()method to deserialize the byte string to a dictionary
This is the function:
def get_post_by_id(id):
'''Get information about a post with ID id
Arg: @id - Post ID
Return: A dictionary with info about the post
'''
from urllib.request import urlopen
import json
try:
if int(id) >= 1 and int(id) <= 100:
with urlopen(f'https://jsonplaceholder.typicode.com/posts/{id}') as response:
return json.loads(response.read())
return 'id must be an integer in the range 1–100'
except:
return 'id must be an integer in the range 1–100'
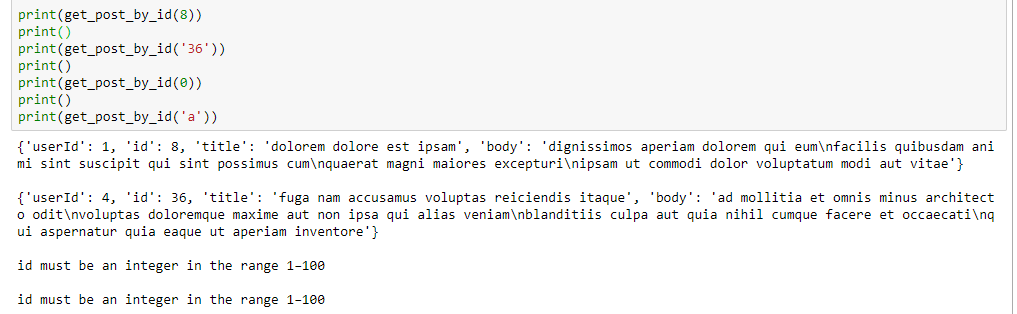
For this API, id can be a number in string format (see Step 2 above). The try/except block ensures that the int(id) comparison raises no exception when id cannot be converted to int. This is the output when you call the function with different kinds of arguments:
TASK 2. Using the same API, write a function that returns all comments to a certain post.
Solution. Each post has an id, so let the function prototype be get_post_comments(post_id). According to the API documentation, the URL for post comments can take two forms: jsonplaceholder.typicode.com/posts{post_id}/comments or jsonplaceholder.typicode.com/comments?postId={post_id}
Here are the steps:
Import the
jsonmodule and theurlopenfunction from theurllib.requestmoduleValidate that
post_idis an integer (or can be converted to an integer) in the range 1–100Use
urlopento get the HTTP response for any of the URL aboveCall the
read()method on the response to convert it to a byte stringUse the
json.loads()method to deserialize the byte string
This is the code:
def get_post_comments(post_id):
'''Get all comments to a post with ID post_id
Arg: @post_id - Post ID
Return: A list of all comments to the post
'''
from urllib.request import urlopen
import json
try:
if int(post_id) >= 1 and int(post_id) <= 100:
with urlopen(f'https://jsonplaceholder.typicode.com/comments?postId={post_id}') as response:
return json.loads(response.read())
return 'id must be an integer in the range 1–100'
except:
return 'id must be an integer in the range 1–100'
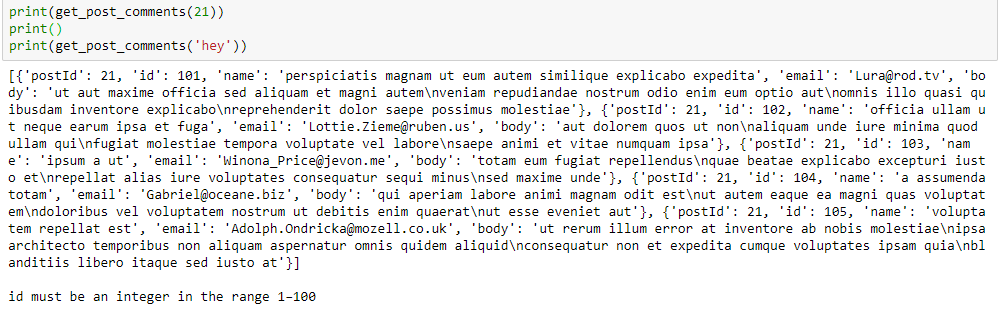
This is the output when the function is called with an integer and a non-numerical string:
The requests module
The requests module is a third-party Python HTTP library. It’s easier to use than the urllib.request library. To use the requests module, you must first install it (if your development environment doesn’t have it preinstalled). After installation, you can then import the module:
import requests
The get() method is used to get a webpage.
response = requests.get(url)
url is the URL of the webpage you want to get. There are many methods and attributes you can call on response: text returns the content of the response in string format, json() decodes the content (if it’s a supported JSON string), and status_code returns the response status code. Check out the Requests documentation to learn more about the module and its methods and attributes.
How to query API using the requests module
The following tasks are more complex than the previous ones. The aim, besides demonstrating how to use the requests module, is to show that requests may be more suitable for more advanced tasks than urllib.request. There will be no input validation for the following tasks.
TASK 3. Write a function that returns a dictionary of a user’s todos. The format of the dictionary should be: { "user USERID": [{"todo": "TODO_TITLE", "completed": TODO_COMPLETION_STATUS, "username": "USERNAME"}, {"todo": "TODO_TITLE", "completed": TODO_COMPLETION_STATUS, "username": "USERNAME"}, ... ]}
All components in uppercase will be replaced dynamically.
Solution. Let the function prototype be user_todos(user_id). Here are the steps:
Import the
requestsmoduleUse the
requests.get()method to get the todosUse the
json()method to convert the todos response to a dictionaryUse the
requests.get()method to get the usersUse the
json()method to convert users to a list of dictionariesGet the element (dictionary) representing the user with the given id
Use the
dict.get()method to get the username for this userSet an empty dictionary (
todos_dict) to hold the user’s todos and an empty list (inner_list) to hold the details of these todosLoop through the todos obtained in step 3 above
Each time, set a dictionary to hold the todo title, the todo completion status and the username of the user who owns the todo
Then append this dictionary to
inner_listof step 8 above
Outside the loop, set a
'user USERID'key fortodos_dictof step 8 and assigninner_listas the value of this keyReturn
todos_dict
This is the code:
def user_todos(user_id):
'''Get information about a user's todos, given the user id.
Arg: @user_id - user id
Return: a dict of this form
{"user USERID":
[{"todo": "TODO_TITLE", "completed": TODO_COMPLETION_STATUS, "username": "USERNAME"},
{"todo": "TODO_TITLE", "completed": TODO_COMPLETION_STATUS, "username": "USERNAME"},
...
]}
'''
import requests
todos = requests.get(f'https://jsonplaceholder.typicode.com/users/{user_id}/todos')
todos = todos.json()
users = requests.get('https://jsonplaceholder.typicode.com/users')
username = users.json()[user_id - 1].get('username')
todos_dict = {}
inner_list = []
for todo in todos:
inner_dict = {}
inner_dict['task'] = todo.get('title')
inner_dict['completed'] = todo.get('completed')
inner_dict['username'] = username
inner_list.append(inner_dict)
todos_dict[f'user {user_id}'] = inner_list
return todos_dict
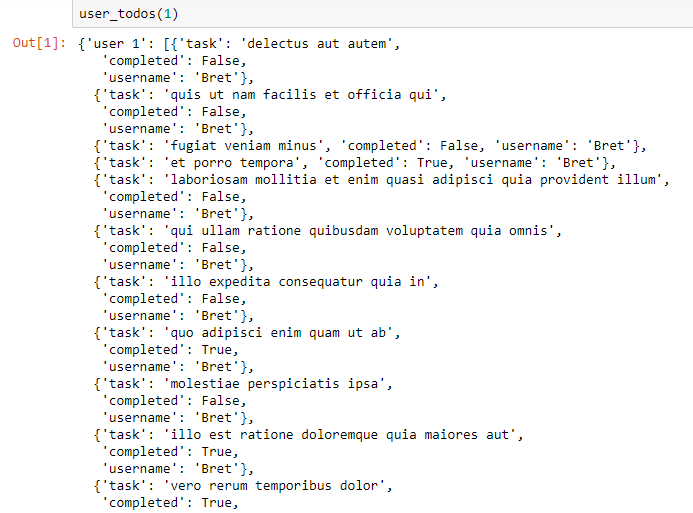
This is a part of the output when the function is called:
TASK 4. Write a function that returns all users’ todos as a dictionary. The format of the dictionary should be: {"user USER_ID": [{"todo": "TODO_TITLE", "completed": TODO_COMPLETION_STATUS, "username": "USERNAME"}, {"todo": "TODO_TITLE", "completed": TODO_COMPLETION_STATUS, "username": "USERNAME"}, ...], "user USER_ID": [{"todo": "TODO_TITLE", "completed": TODO_COMPLETION_STATUS, "username": "USERNAME"}, {"todo": "TODO_TITLE", "completed": TODO_COMPLETION_STATUS, "username": "USERNAME"}, ...], ...}
Solution. Let the function prototype be all_users_todos(). Here are the steps:
Import the
requestsmoduleSet a list of user ids (there are 10 users).
Use the
requests.get()method to get the usersSet an empty dict,
todos_dict, to hold the details of each user’s todosLoop through
user_ids(step 2). For eachid:Get the todos for the user using
requests.get()Use the
json()method to convertusers(step 3) to a list of dictionariesGet the element (dictionary) representing the user with the current
idUse the
dict.get()method to get the username for this userSet an empty list
inner_listLoop through the todos (Step 5.1). For each todo:
Set an empty dict
inner_dictSet
inner_dict['username']tousername(step 5.4)Use
dict.get()to get the todo title and assign it toinner_dict['task']Use
dict.get()to get the todo completion status and assign it toinner_dict['completed']Append
inner_dicttoinner_list(step 5.5)
Outside the inner loop but inside the outer loop, set a
'user USERID'key fortodos_dict(step 4) and assigninner_listas the value of this key.
Outside the outer loop, return
todos_dict
This is the code:
def all_users_todos():
"""Get info about all users' todos
Return: a dict of this form
{"user USER_ID": [{"todo": "TODO_TITLE", "completed": TODO_COMPLETION_STATUS, "username": "USERNAME"},
{"todo": "TODO_TITLE", "completed": TODO_COMPLETION_STATUS, "username": "USERNAME"}, ...],
"user USER_ID": [{"todo": "TODO_TITLE", "completed": TODO_COMPLETION_STATUS, "username": "USERNAME"},
{"todo": "TODO_TITLE", "completed": TODO_COMPLETION_STATUS, "username": "USERNAME"}, ...],
...}
"""
import requests
user_ids = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
users = requests.get('https://jsonplaceholder.typicode.com/users')
todos_dict = {}
for id in user_ids:
todos = requests.get(f'https://jsonplaceholder.typicode.com/users/{id}/todos')
username = users.json()[id - 1].get('username')
inner_list = []
for todo in todos.json():
inner_dict = {}
inner_dict['username'] = username
inner_dict['task'] = todo.get('title')
inner_dict['completed'] = todo.get('completed')
inner_list.append(inner_dict)
todos_dict[f'user {id}'] = inner_list
return todos_dict
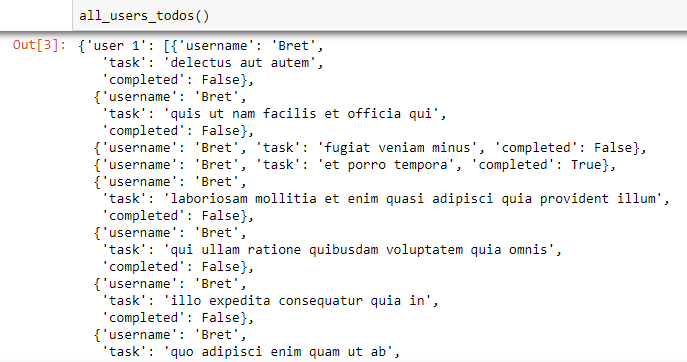
This is some sections of the output when the function is called:

Conclusion
The urllib.request and requests packages are Python libraries for making HTTP requests. Focusing only on GET methods, we have seen how these packages can be used to query APIs. While this article has only scratched the surface of the full power of these packages, I hope you are now curious to explore them more.